参考文章
https://zhuanlan.zhihu.com/p/34133067
https://blog.csdn.net/azurelaker/article/details/85045245
https://www.bilibili.com/video/av45625512
最近在使用redis,然后看到了redis与LRU相关的一些内容,再此对之前所看的一些博文进行总结
一、什么是LRU
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间t,当须淘汰一个页面时,选择现有页面中其t值最大的,即最近最少使用的页面予以淘汰。
二、如何实现LRU
如果按照访问时间进行了排序,会有大量的内存拷贝操作,所以性能肯定是不能接受的。那么如何设计一个LRU缓存,使得放入和移除都是O(1)的,我们需要把访问次序维护起来,但是不能通过内存中的真实排序来反应,有一种方案就是使用双向链表。
三、基于HashMap和双向链表实现LRU
在这个双向链表中存在一个HashMap用于存储实现LRU的双向链表的节点,如图所示
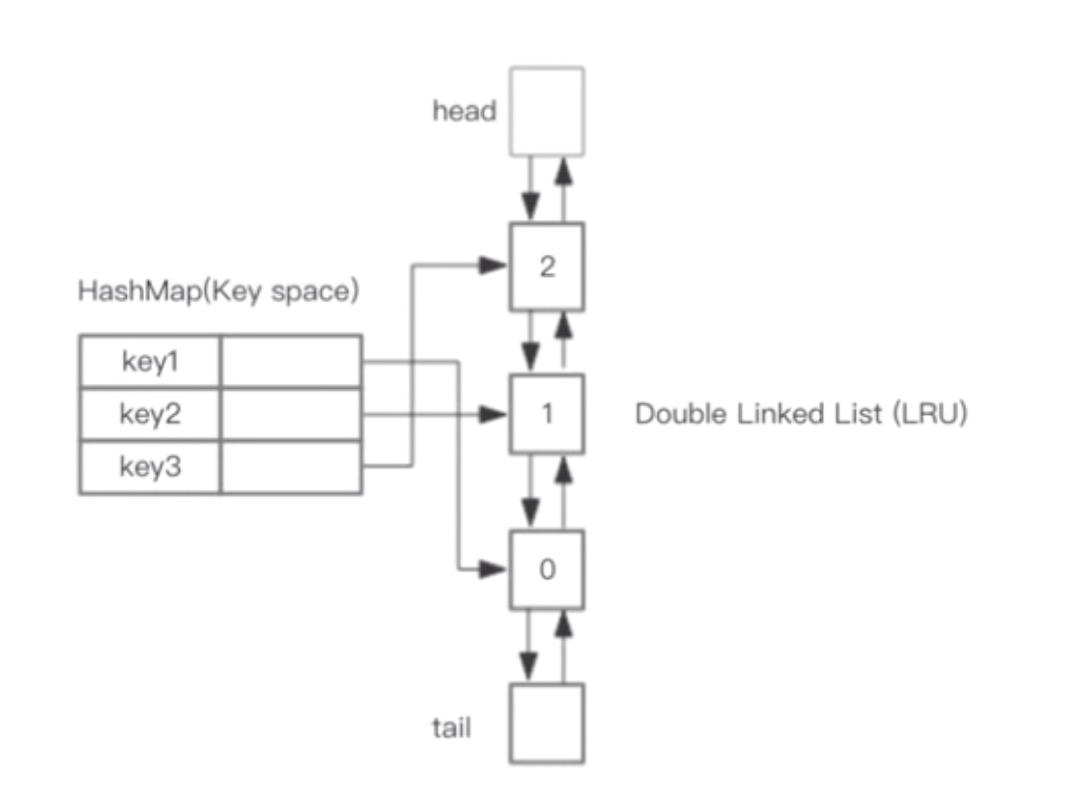
而双向链表则存在一个head和一个tail分别指代双向链表的头与尾。
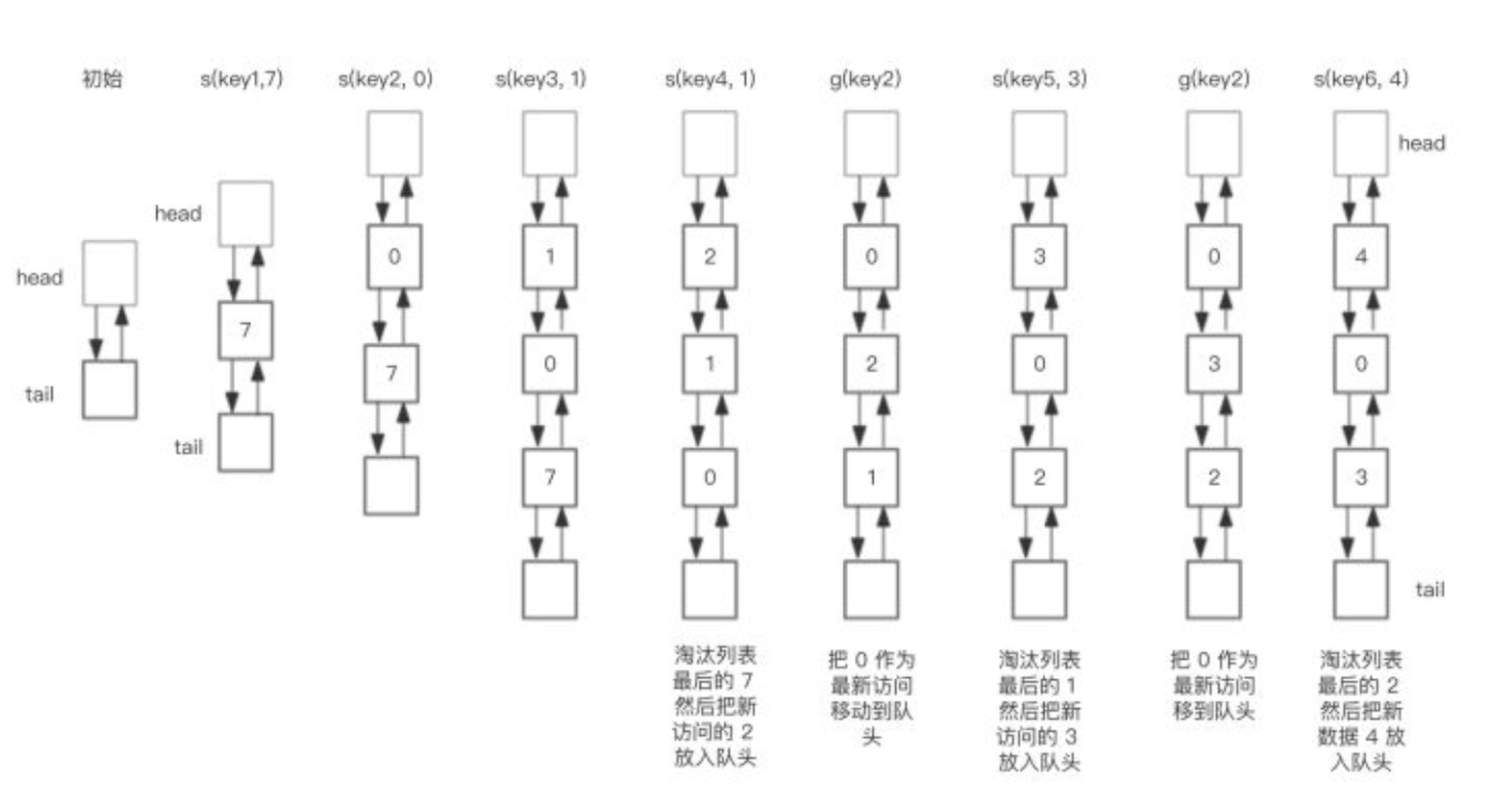
假设我们预设一个大小为3的cache,当我们执行以下操作时,1
2
3
4
5
6
7
8save("key1", 7)
save("key2", 0)
save("key3", 1)
save("key4", 2)
get("key2")
save("key5", 3)
get("key2")
save("key6", 4)
双向链表变化如图所示:
四、LRU的Java实现
1 | //节点数据结构 |
实际操作代码实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93class LRUache{
private HashMap<Integer, DLinkedNode> cache = new HashMap<>();
//目前双向链表中的节点数
private int count;
//最大容量
private int capacity;
//双向链表头尾节点
private DLinkedNode head, tail;
public LRUache(int capacity){
this.count = 0;
this.capacity = capacity;
head = new DLinkedNode();
head.pre = null;
tail = new DLinkedNode();
tail.next = null;
head.next = tail;
tail.pre = head;
}
//将节点挪至头部
private void moveToHead(DLinkedNode node){
//清除当前节点,即将当前节点的pre节点和next节点相连
removeNode(node);
//根据LRU算法,将操作的节点放至首位置
addNode(node);
}
//将该节点挪除
private void removeNode(DLinkedNode node){
DLinkedNode pre = node.pre;
DLinkedNode next = node.next;
pre.next = next;
next.pre = pre;
}
//在头部添加节点
private void addNode(DLinkedNode node){
node.pre = head;
node.next = head.next;
head.next.pre = node;
head.next = node;
}
//清除超出最大容量后的最后一个节点
private DLinkedNode popTail(){
DLinkedNode node = tail.pre;
removeNode(node);
return node;
}
//获取节点并更新LRU
public int get(int key){
DLinkedNode node = cache.get(key);
if(node == null){
return -1;
}
moveToHead(node);
return node.val;
}
//压入新节点
public void put(int key, int value){
DLinkedNode node = cache.get(key);
if(node == null){
DLinkedNode newNode = new DLinkedNode();
newNode.key = key;
newNode.value = value;
cache.put(key, value);
addNode(newNode);
count++;
if(count > capacity){
DLinkedNode tail = popTail();
cache.remove(tail.key);
count--;
}
}else{
node.value = value;
moveToHead(node);
}
}
}
五、Redis的LRU实现
Redis系统中与LRU功能相关的配置参数有三个:
maxmemory: 该参数即为缓存数据占用的内存限制. 当缓存的数据消耗的内存超过这个数值限制时, 将触发数据淘汰. 该数据配置为0时,表示缓存的数据量没有限制, 即LRU功能不生效.maxmemory_policy: 淘汰策略. 定义参与淘汰的数据的类型和属性.maxmemory_samples: 随机采样的精度. 该数值配置越大, 越接近于真实的LRU算法,但是数值越大, 消耗的CPU计算时间越多,执行效率越低.
我们知道在Redis缓存中可以有超时属性所以Redis在每个数据库结构中使用了两个不同的哈希表来管理缓存数据. 数据结构如下:1
2
3
4
5
6
7
8
9
10//redis.h
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id;
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;
由助手可知 expires存储含有超时属性的数据,而dict则可以存储所有的数据。
Redis一共提供了六种淘汰策略,即参数maxmemory_policy有六种取值:
noeviction: 如果缓存数据超过了maxmemory限定值,并且客户端正在执行的命令会导致内存分配,则向客户端返回错误响应.allkeys-lru: 所有的缓存数据(包括没有超时属性的和具有超时属性的)都参与LRU算法淘汰.volatile-lru: 只有超时属性的缓存数据才参与LRU算法淘汰.allkeys-random: 所有的缓存数据(包括没有超时属性的和具有超时属性的)都参与淘汰, 但是采用随机淘汰,而不是用LRU算法进行淘汰.volatile-random: 只有超时属性的缓存数据才参与淘汰,但是采用随机淘汰,而不是用LRU算法进行淘汰.volatile-ttl: 只有超时属性的缓存数据才参与淘汰. 根据缓存数据的超时TTL进行淘汰,而不是用LRU算法进行淘汰.
注: volatile-lru,volatile-random和volatile-ttl这三种淘汰策略不是使用的全量数据,所以可能会导致无法淘汰出足够的内存空间。而且当设置超时属性时属性会占用更大的内存,所以当内存压力比较大时要慎用超时属性。
redis处理流程
1.客户端向redis发送消息,redis对命令进行解析,为命令分配内存。
2.判断内存是否超出限定值,即maxmemory,如果超过,则按照所选定的淘汰算法,进行内存释放。
3.当指令为读指令时忽略淘汰算法,当为写指令,且超出限定值进行内存释放,若内存释放失败则向客户端返回错误响应,如释放成功则执行写指令。
redis源码解析
Redis处理命令的入口函数
processCommand
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
int processCommand(redisClient *c) {
/* The QUIT command is handled separately. Normal command procs will
* go through checking for replication and QUIT will cause trouble
* when FORCE_REPLICATION is enabled and would be implemented in
* a regular command proc. */
if (!strcasecmp(c->argv[0]->ptr,"quit")) {
addReply(c,shared.ok);
c->flags |= REDIS_CLOSE_AFTER_REPLY;
return REDIS_ERR;
}
/* Now lookup the command and check ASAP about trivial error conditions
* such as wrong arity, bad command name and so forth. */
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
if (!c->cmd) {
flagTransaction(c);
addReplyErrorFormat(c,"unknown command '%s'",
(char*)c->argv[0]->ptr);
return REDIS_OK;
} else if ((c->cmd->arity > 0 && c->cmd->arity != c->argc) ||
(c->argc < -c->cmd->arity)) {
flagTransaction(c);
addReplyErrorFormat(c,"wrong number of arguments for '%s' command",
c->cmd->name);
return REDIS_OK;
}
/* Check if the user is authenticated */
if (server.requirepass && !c->authenticated && c->cmd->proc != authCommand)
{
flagTransaction(c);
addReply(c,shared.noautherr);
return REDIS_OK;
}
/* Handle the maxmemory directive.
*
* First we try to free some memory if possible (if there are volatile
* keys in the dataset). If there are not the only thing we can do
* is returning an error. */
if (server.maxmemory) {
int retval = freeMemoryIfNeeded();
/* freeMemoryIfNeeded may flush slave output buffers. This may result
* into a slave, that may be the active client, to be freed. */
if (server.current_client == NULL) return REDIS_ERR;
/* It was impossible to free enough memory, and the command the client
* is trying to execute is denied during OOM conditions? Error. */
if ((c->cmd->flags & REDIS_CMD_DENYOOM) && retval == REDIS_ERR) {
flagTransaction(c);
addReply(c, shared.oomerr);
return REDIS_OK;
}
}
/* Don't accept write commands if there are problems persisting on disk
* and if this is a master instance. */
if (((server.stop_writes_on_bgsave_err &&
server.saveparamslen > 0 &&
server.lastbgsave_status == REDIS_ERR) ||
server.aof_last_write_status == REDIS_ERR) &&
server.masterhost == NULL &&
(c->cmd->flags & REDIS_CMD_WRITE ||
c->cmd->proc == pingCommand))
{
flagTransaction(c);
if (server.aof_last_write_status == REDIS_OK)
addReply(c, shared.bgsaveerr);
else
addReplySds(c,
sdscatprintf(sdsempty(),
"-MISCONF Errors writing to the AOF file: %s\r\n",
strerror(server.aof_last_write_errno)));
return REDIS_OK;
}
/* Don't accept write commands if there are not enough good slaves and
* user configured the min-slaves-to-write option. */
if (server.masterhost == NULL &&
server.repl_min_slaves_to_write &&
server.repl_min_slaves_max_lag &&
c->cmd->flags & REDIS_CMD_WRITE &&
server.repl_good_slaves_count < server.repl_min_slaves_to_write)
{
flagTransaction(c);
addReply(c, shared.noreplicaserr);
return REDIS_OK;
}
/* Don't accept write commands if this is a read only slave. But
* accept write commands if this is our master. */
if (server.masterhost && server.repl_slave_ro &&
!(c->flags & REDIS_MASTER) &&
c->cmd->flags & REDIS_CMD_WRITE)
{
addReply(c, shared.roslaveerr);
return REDIS_OK;
}
/* Only allow SUBSCRIBE and UNSUBSCRIBE in the context of Pub/Sub */
if (c->flags & REDIS_PUBSUB &&
c->cmd->proc != pingCommand &&
c->cmd->proc != subscribeCommand &&
c->cmd->proc != unsubscribeCommand &&
c->cmd->proc != psubscribeCommand &&
c->cmd->proc != punsubscribeCommand) {
addReplyError(c,"only (P)SUBSCRIBE / (P)UNSUBSCRIBE / QUIT allowed in this context");
return REDIS_OK;
}
/* Only allow INFO and SLAVEOF when slave-serve-stale-data is no and
* we are a slave with a broken link with master. */
if (server.masterhost && server.repl_state != REDIS_REPL_CONNECTED &&
server.repl_serve_stale_data == 0 &&
!(c->cmd->flags & REDIS_CMD_STALE))
{
flagTransaction(c);
addReply(c, shared.masterdownerr);
return REDIS_OK;
}
/* Loading DB? Return an error if the command has not the
* REDIS_CMD_LOADING flag. */
if (server.loading && !(c->cmd->flags & REDIS_CMD_LOADING)) {
addReply(c, shared.loadingerr);
return REDIS_OK;
}
/* Lua script too slow? Only allow a limited number of commands. */
if (server.lua_timedout &&
c->cmd->proc != authCommand &&
c->cmd->proc != replconfCommand &&
!(c->cmd->proc == shutdownCommand &&
c->argc == 2 &&
tolower(((char*)c->argv[1]->ptr)[0]) == 'n') &&
!(c->cmd->proc == scriptCommand &&
c->argc == 2 &&
tolower(((char*)c->argv[1]->ptr)[0]) == 'k'))
{
flagTransaction(c);
addReply(c, shared.slowscripterr);
return REDIS_OK;
}
/* Exec the command */
if (c->flags & REDIS_MULTI &&
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand)
{
queueMultiCommand(c);
addReply(c,shared.queued);
} else {
call(c,REDIS_CALL_FULL);
if (listLength(server.ready_keys))
handleClientsBlockedOnLists();
}
return REDIS_OK;
}
当调用该函数时,Redis已经解析完命令以及参数,并分配了内存空间,客户端对象的argv字段指向这些分配的内存空间.
LINE 40 - 53调用函数freeMemoryIfNeeded释放缓存的内存空间,如果freeMemoryIfNeeded返回失败,即无法释放足够的内存,并且客户端命令是导致内存增加的命令,则向客户端返回OOM错误消息响应.
函数freeMemoryIfNeeded淘汰缓存的数据,其实现为(redis.c):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150int freeMemoryIfNeeded(void) {
size_t mem_used, mem_tofree, mem_freed;
int slaves = listLength(server.slaves);
mstime_t latency;
/* Remove the size of slaves output buffers and AOF buffer from the
* count of used memory. */
mem_used = zmalloc_used_memory();
if (slaves) {
listIter li;
listNode *ln;
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
redisClient *slave = listNodeValue(ln);
unsigned long obuf_bytes = getClientOutputBufferMemoryUsage(slave);
if (obuf_bytes > mem_used)
mem_used = 0;
else
mem_used -= obuf_bytes;
}
}
if (server.aof_state != REDIS_AOF_OFF) {
mem_used -= sdslen(server.aof_buf);
mem_used -= aofRewriteBufferSize();
}
/* Check if we are over the memory limit. */
if (mem_used <= server.maxmemory) return REDIS_OK;
if (server.maxmemory_policy == REDIS_MAXMEMORY_NO_EVICTION)
return REDIS_ERR; /* We need to free memory, but policy forbids. */
/* Compute how much memory we need to free. */
mem_tofree = mem_used - server.maxmemory;
mem_freed = 0;
latencyStartMonitor(latency);
while (mem_freed < mem_tofree) {
int j, k, keys_freed = 0;
for (j = 0; j < server.dbnum; j++) {
long bestval = 0; /* just to prevent warning */
sds bestkey = NULL;
struct dictEntry *de;
redisDb *db = server.db+j;
dict *dict;
if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_RANDOM)
{
dict = server.db[j].dict;
} else {
dict = server.db[j].expires;
}
if (dictSize(dict) == 0) continue;
/* volatile-random and allkeys-random policy */
if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_RANDOM ||
server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_RANDOM)
{
de = dictGetRandomKey(dict);
bestkey = dictGetKey(de);
}
/* volatile-lru and allkeys-lru policy */
else if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
{
for (k = 0; k < server.maxmemory_samples; k++) {
sds thiskey;
long thisval;
robj *o;
de = dictGetRandomKey(dict);
thiskey = dictGetKey(de);
/* When policy is volatile-lru we need an additional lookup
* to locate the real key, as dict is set to db->expires. */
if (server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
de = dictFind(db->dict, thiskey);
o = dictGetVal(de);
thisval = estimateObjectIdleTime(o);
/* Higher idle time is better candidate for deletion */
if (bestkey == NULL || thisval > bestval) {
bestkey = thiskey;
bestval = thisval;
}
}
}
/* volatile-ttl */
else if (server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_TTL) {
for (k = 0; k < server.maxmemory_samples; k++) {
sds thiskey;
long thisval;
de = dictGetRandomKey(dict);
thiskey = dictGetKey(de);
thisval = (long) dictGetVal(de);
/* Expire sooner (minor expire unix timestamp) is better
* candidate for deletion */
if (bestkey == NULL || thisval < bestval) {
bestkey = thiskey;
bestval = thisval;
}
}
}
/* Finally remove the selected key. */
if (bestkey) {
long long delta;
robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
propagateExpire(db,keyobj);
/* We compute the amount of memory freed by dbDelete() alone.
* It is possible that actually the memory needed to propagate
* the DEL in AOF and replication link is greater than the one
* we are freeing removing the key, but we can't account for
* that otherwise we would never exit the loop.
*
* AOF and Output buffer memory will be freed eventually so
* we only care about memory used by the key space. */
delta = (long long) zmalloc_used_memory();
dbDelete(db,keyobj);
delta -= (long long) zmalloc_used_memory();
mem_freed += delta;
server.stat_evictedkeys++;
notifyKeyspaceEvent(REDIS_NOTIFY_EVICTED, "evicted",
keyobj, db->id);
decrRefCount(keyobj);
keys_freed++;
/* When the memory to free starts to be big enough, we may
* start spending so much time here that is impossible to
* deliver data to the slaves fast enough, so we force the
* transmission here inside the loop. */
if (slaves) flushSlavesOutputBuffers();
}
}
if (!keys_freed) {
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("eviction-cycle",latency);
return REDIS_ERR; /* nothing to free... */
}
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("eviction-cycle",latency);
return REDIS_OK;
}
执行if (mem_used <= server.maxmemory) return REDIS_OK;如果当前缓存数据占用的总的内存小于配置的maxmemory,则不用淘汰,直接返回.
如果当前缓存的数据使用的内存大于配置的maxmemory,并且淘汰策略不允许释放内存(noeviction),则该函数返回失败.
接下来,局部变量mem_tofree表示需要淘汰的内存,局部变量mem_freed表示已经淘汰的内存.循环执行while (mem_freed < mem_tofree)淘汰缓存数据,该循环中的逻辑可以概括为:
- 从全局的0号数据库开始(Redis默认有16个全局的数据库),根据淘汰策略,选择该数据库中的哈希表.如果该哈希表为空, 选择下一个全局数据库.
- 根据淘汰策略,在相应哈希表中找到一个待淘汰的key, 从该数据库对象中删除该key所对应的缓存数据.
- 如果没有找到待淘汰的key,即无法淘汰所需的缓存数据大小 函数直接返回错误.
- 如果当前访问的是最后一个全局数据库, 并且已经淘汰了所需的缓存数据,则该函数成功返回.如果没有淘汰所需的缓存数据,则返回步骤1,并且从0号数据库重新淘汰.如果当前访问的不是最后一个全局数据库, 则返回步骤1, 从当前数据库的下一个数据库继续淘汰缓存数据.
如果淘汰策略是allkeys-random或者volatile-random,则从相应数据库中随机选择一个key进行淘汰.
如果淘汰策略是allkeys-lru或者volatile-lru, 则根据配置的采样值maxmemory_samples,随机从数据库中选择maxmemory_samples个key, 淘汰其中热度最低的key对应的缓存数据.
如果淘汰策略是volatile-ttl,则根据配置的采样值maxmemory_samples,随机从数据库中选择maxmemory_samples个key,淘汰其中最先要超时的key对应的缓存数据.
所以采样参数maxmemory_samples配置的数值越大, 就越能精确的查找到待淘汰的缓存数据,但是也消耗更多的CPU计算,执行效率降低.
从数据库的哈希表结构中随机返回一个key的执行函数为dictGetRandomKey, 其实现为(dict.c):
1 | /* Return a random entry from the hash table. Useful to |
上述代码主要执行了两件事情:
- 首先在哈希表中随机选择一个非空的桶(bucket).
- 在该桶的冲突链表中随机选择一个节点.
根据LRU淘汰算法的属性,如果缓存的数据被频繁访问, 其热度就高,反之,热度低. 下面说明缓存数据的热度相关的细节.
Redis中的对象结构定义为(redis.h):1
2
3
4
5
6
7typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
即对象结构中存在一个lru字段, 且使用了unsigned的低24位(REDIS_LRU_BITS定义的值).
Redis命令访问缓存的数据时,均会调用函数lookupKey, 其实现为(db.c):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15robj *lookupKey(redisDb *db, robj *key) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
/* Update the access time for the ageing algorithm.
* Don't do it if we have a saving child, as this will trigger
* a copy on write madness. */
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1)
val->lru = server.lruclock;
return val;
} else {
return NULL;
}
}
该函数会更新对象的lru值, 设置为全局的server.lruclock值.当然,在对象创建的时候也会将该lru字段设置为全局的server.lruclock.
全局的server.lruclock是在函数serverCron中调用函数updateLRUClock更新的(redis.c):1
2
3
4void updateLRUClock(void) {
server.lruclock = (server.unixtime/REDIS_LRU_CLOCK_RESOLUTION) &
REDIS_LRU_CLOCK_MAX;
}
而全局的server.unixtime是在函数serverCron中调用函数updateCachedTime更新的(redis.c):1
2
3
4
5
6
7
8/* We take a cached value of the unix time in the global state because with
* virtual memory and aging there is to store the current time in objects at
* every object access, and accuracy is not needed. To access a global var is
* a lot faster than calling time(NULL) */
void updateCachedTime(void) {
server.unixtime = time(NULL);
server.mstime = mstime();
}
函数serverCron是定时器执行函数, 会周期性执行.Redis系统中全局变量server.hz设置为10, 则serverCron的调度周期为100毫秒.也就是说,全局变量server.lruclock会每隔100毫秒得到更新,该字段也和对象结构的lru字段一样,也是使用了unsigned的低24位.
所以函数lookupKey中更新缓存数据的lru热度值时,不是调用的系统函数获得的当前时间戳,而是该值的一个近似值server.lruclock, 这样不用每次调用系统函数,可以提高执行效率.
函数estimateObjectIdleTime评估指定对象的lru热度,其实现为(object.c):
1 | /* Given an object returns the min number of seconds the object was never |
其思想就是对象的lru热度值和全局的server.lruclock的差值越大, 该对象热度越低.但是,因为全局的server.lruclock数值有可能发生溢出(超过REDIS_LRU_CLOCK_MAX则溢出), 所以对象的lru数值可能大于server.lruclock数值. 所以计算二者的差值时,需考虑二者间的大小关系.
Redis系统没有使用一个全局的链表将所有的缓存数据管理起来,而是使用一种近似的算法来模拟LRU淘汰的效果:
- 首先可以节省内存占用.如果用全局的双向链表管理所有的缓存数据,则每个节点的两个指针字段将增加16字节(64位系统上).
- Redis系统中不同对象实现的可能是不同的结构,有的是比较复杂的复合结构. 如果再引入一个全局的链表,将增加代码复杂性,可读性也变差.
六、常见缓存算法总结
1.LRU
LRU全称是Least Recently Used,即最近最久未使用的意思。如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。而用什么数据结构来实现LRU算法呢?
可能大多数人都会想到:用一个数组来存储数据,给每一个数据项标记一个访问时间戳,每次插入新数据项的时候,先把数组中存在的数据项的时间戳自增,并将新数据项的时间戳置为0并插入到数组中。每次访问数组中的数据项的时候,将被访问的数据项的时间戳置为0。当数组空间已满时,将时间戳最大的数据项淘汰。这种实现思路很简单,但是有什么缺陷呢?需要不停地维护数据项的访问时间戳,另外,在插入数据、删除数据以及访问数据时,时间复杂度都是O(n)。
那么有没有更好的实现办法呢?
那就是利用链表移动访问时间的数据顺序和hashmap查询是否是新数据项。当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
2.LFU
LFU(Least Frequently Used)最近最少使用算法。它是基于“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小”的思路。
注意LFU和LRU算法的不同之处,LRU的淘汰规则是基于访问时间,而LFU是基于访问次数的。举个简单的例子:
假设缓存大小为3,数据访问序列为set(2,2),set(1,1),get(2),get(1),get(2),set(3,3),set(4,4),
则在set(4,4)时对于LFU算法应该淘汰(3,3),而LRU应该淘汰(1,1)。
为了能够淘汰最少使用的数据,因此LFU算法最简单的一种设计思路就是 利用一个数组存储 数据项,用hashmap存储每个数据项在数组中对应的位置,然后为每个数据项设计一个访问频次,当数据项被命中时,访问频次自增,在淘汰的时候淘汰访问频次最少的数据。这样一来的话,在插入数据和访问数据的时候都能达到O(1)的时间复杂度,在淘汰数据的时候,通过选择算法得到应该淘汰的数据项在数组中的索引,并将该索引位置的内容替换为新来的数据内容即可,这样的话,淘汰数据的操作时间复杂度为O(n)。
3.FIFO
FIFO(First in First out),先进先出。其实在操作系统的设计理念中很多地方都利用到了先进先出的思想,比如作业调度(先来先服务),为什么这个原则在很多地方都会用到呢?因为这个原则简单、且符合人们的惯性思维,具备公平性,并且实现起来简单,直接使用数据结构中的队列即可实现。在FIFO Cache设计中,核心原则就是:如果一个数据最先进入缓存中,则应该最早淘汰掉。
那么利用什么数据结构来实现呢?
下面提供一种实现思路:利用一个双向链表保存数据,当来了新的数据之后便添加到链表末尾,如果Cache存满数据,则把链表头部数据删除,然后把新的数据添加到链表末尾。在访问数据的时候,如果在Cache中存在该数据的话,则返回对应的value值;否则返回-1。如果想提高访问效率,可以利用hashmap来保存每个key在链表中对应的位置。