环境
- CentOS 7
- JAVA 1.8
- Zookeeper 2.9.2
- Hadoop 3.4.14
一、简单HDFS集群中存在的问题及解决办法
如何解决NameNode的单节点问题
多个NameNode备份原NameNode数据
如何解决多个NameNode是集群脑裂问题
使用QJM,QJM(Quorum Journal Manager)是Hadoop专门为Namenode共享存储开发的组件。其集群运行一组Journal Node,每个Journal 节点暴露一个简单的RPC接口,允许Namenode读取和写入数据,数据存放在Journal节点的本地磁盘。当Namenode写入edit log时,它向集群的所有Journal Node发送写入请求,当多数节点回复确认成功写入之后,edit log就认为是成功写入。例如有3个Journal Node,Namenode如果收到来自2个节点的确认消息,则认为写入成功。
而在故障自动转移的处理上,引入了监控Namenode状态的ZookeeperFailController(ZKFC)。ZKFC一般运行在Namenode的宿主机器上,与Zookeeper集群协作完成故障的自动转移。整个集群架构图如下:
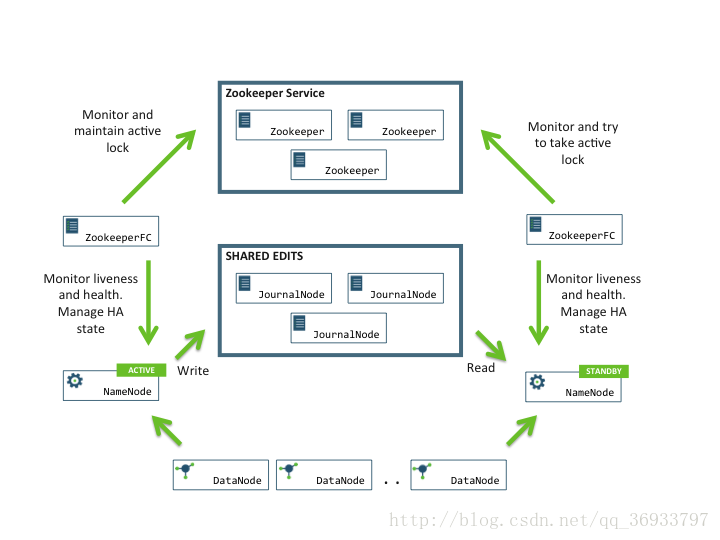
在HA集群中如何ZK与
NameNode active出现网络延迟问题这种情况,ZK会自动将NameNode standby切换为活跃节点,这个时候就出现了多个active节点,也就意味着现有集群面临脑裂问题
使用JournalNode- 负责NameNode的edit log同步
- JournalNode隔离机制,保证在一个时刻只有一个NameNode active,使用ssh登录到NameNode节点使用kill命令杀死NameNode。
二、集群规划
1. 相关要求:
- 节点个数最好是奇数个 3个节点
- 每个zookeeper服务会启动至少三个端口
- 1.client处理
- 2.内部数据原子广播
- 3.内部选举投票端口
2. 服务器相关信息
| hostname | 所运行服务 | IP地址 |
|---|---|---|
| zk1 | zkNode1 | 按照实际IP地址 |
| zk2 | zkNode2 | 按照实际IP地址 |
| zk3 | zkNode3 | 按照实际IP地址 |
| hadoop1 | NameNode(active) & DataNode & JournalNode & ZKFC | 按照实际IP地址 |
| hadoop2 | NameNode(standby) & DataNode & JournalNode & ZKFC | 按照实际IP地址 |
| hadoop3 | DataNode & JournalNode & ZKFC | 按照实际IP地址 |
3. 共同配置
(1) 修改所有机器hostname1
vi /etc/hostname
(2) 配置hosts文件,将ip地址与主机名进行映射1
vi /etc/hosts
(3) 重启机器
(4) 配置ssh免密登录,实现start-dfs.sh执行的机器可以免密登录其他的NameNode和DataNode节点1
2
3
41. hadoop1: ssh-keygen -t -rsa
2. hadoop1: ssh-copy-id hadoop1
3. hadoop1: ssh-copy-id hadoop2
4. hadoop1: ssh-copy-id hadoop3
(5) 配置JAVA环境
(6) 修改环境变量1
2
3
4
5
6
7
8
9
10#进入配置文件
vi /etc/profile
# 添加如下配置
export JAVA_HOME=/usr/java/jdk1.8.0_251-amd64
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
# 更新配置
source /etc/profile
三、zk集群搭建
1. 解压zookeeper文件
1 | tar -zxvf zookeeper文件 |
2. 在每一个zk节点上创建zk的数据目录
1 | mkdir /home/zkdata |
3. 在每一个节点存放zk数据的目录中必须创建一个myid文件
1 | zk1: echo "1" >> /home/zkdata/myid |
4. 创建zookeeper的基础配置文件zoo.cfg
1 | vi /home/zkdata/zoo.cfg |
配置内容如下1
2
3
4
5
6
7
8
9
10
11# 3001为client端口
# 3002为原子广播端口
# 3003为选举投票端口
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/zkdata
clientPort=3001
server.1=zk1:3002:3003
server.2=zk2:3002:3003
server.3=zk3:3002:3003
5. 启动zk节点,进入zk文件的bin目录下执行以下命令
1 | ./zkServer.sh start /home/zkdata/zoo.cfg |
6. 执行jps命令发现已成功启动QuorumPeerMain进程
7. 查询各个zk节点的集群状态,发现其中一个节点为leader其余节点为follower
1 | ./zkServer.sh status /home/zkdata/zoo.cfg |
8. zk集群搭建完毕
四、HDFS集群搭建
1. 在所有hadoop节点添加Cent OS依赖
1 | yum install psmisc -y |
2. 安装hadoop(配置Hadoop环境变量 非必须)
1 | # 添加如下配置 |
(1) 配置hadoop-env.sh
修改JAVA相关配置
(2) 配置core-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop-2.9.2/data</value>
</property>
<!-- 配置zk集群节点数 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:3001,zk2:3001,zk3:3001</value>
</property>
</configuration>
(3) 配置hdfs-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62<configuration>
<!-- 指定hdfs的nameservices为ns,需要与core-site.xml中保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个nameNode分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的rpc通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop1:50070</value>
</property>
<!-- nn2的rpc通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop2:50070</value>
</property>
<!-- 指定nameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns</value>
</property>
<!-- 指定journalNode在本地磁盘中存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/zhangjia/journal</value>
</property>
<!-- 开启nameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制。如果ssh默认是22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/.ssh/id_rsa</value>
</property>
</configuration>
(4) 配置slaves1
2
3hadoop1
hadoop2
hadoop3
(5) 启动集群
(6) 在任意NameNode节点格式化Zk1
hdfs zkfc -formatZK
(7) 出现下面这句话则说明格式化成功1
ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns in ZK.
(8) 启动JournalNode节点
因为Journal在HA中需要同步edit log,所以他需要在edit log没有生成之前启动
2
3
hadoop2: hadoop-daemon.sh start journalnode
hadoop3: hadoop-daemon.sh start journalnode
(9) 使用jps发现JournalNode进程已启动并且在根文件夹出现journal文件夹
(10) 格式化NameNode,在选中的active的节点上执行1
hdfs namenode -format ns
(11) 启动hdfs集群1
start-dfs.sh
(12) 在standby 的 NameNode节点上执行如下命令进行同步active节点的edit log1
hdfs namenode -bootstrapStandby
(13) 启动standby节点的NameNode1
hadoop-daemon.sh start namenode
此时进入两个NameNode节点的图形化界面 http://hadoop1:50070 可以发现一个为active一个为standby
(14) 此时HA集群搭建完毕