1. spark运行架构
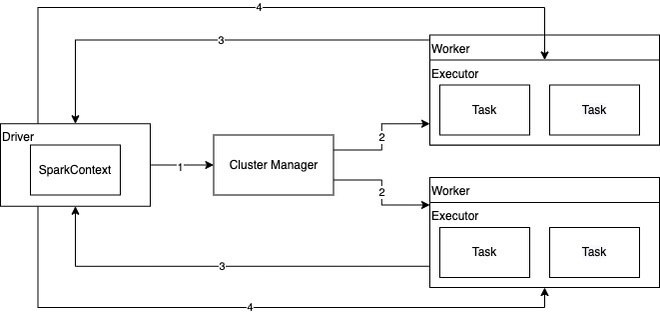
- 当
Spark应用提交时,根据提交的参数在Driver中创建进程,初始化SparkContext对象。并找到Cluster Manager(Master)进程,对Spark应用进行注册。 - 当
Master收到Spark应用注册申请,会发送请求给Worker,进行资源的调度和分配。 - Worker收到Master请求后,会为Spark应用启动
Executor进程。具体数量由参数决定。Executor启动后,会向Driver反注册,这样Driver就可以知道哪些Executor在运行。 - Driver会根据我们对RDD定义的操作,提交一堆的
Task去Executor上执行,Task里面执行的就是具体的map、flatMap这些操作。
2.一个spark程序的执行流程
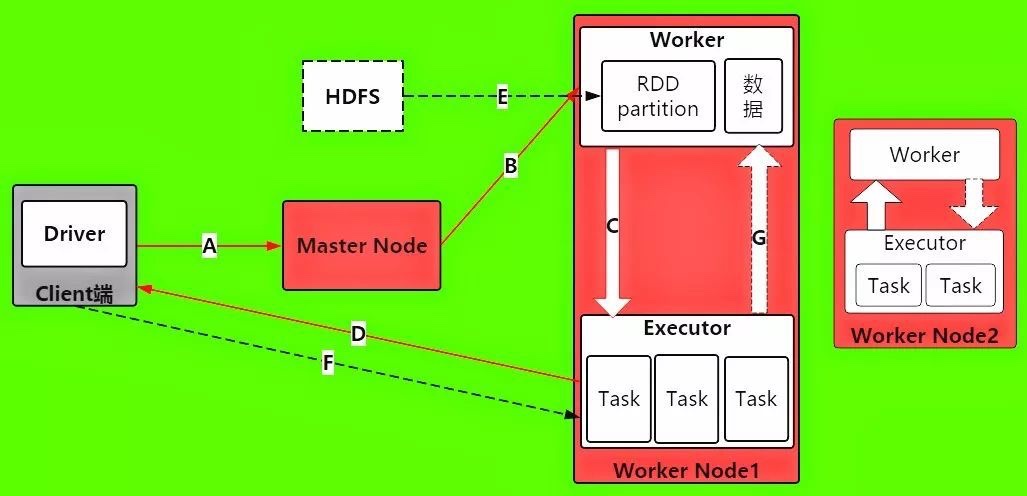
A: 每当Driver进程被启动之后,都会做哪些事情来初始化操作呢?首先它将发送请求到Master上,进行Spark应用程序的注册,也就是我们要让Master知道,现在有一个新的Spark应用程序要运行了。
B: 那Master在接收到Spark应用程序的注册申请之后,会发送给Worker,让其进行资源的调度和分配。这也说明资源分配是由executor来分配管理。
C: Worter接收Master的请求之后,会为Spark应用启动Executor,来给分配资源。
D: Executor启动分配资源好后,就会向Driver进行反注册,这也Driver就会知道哪些Executor是为他进行服务的了。
E: 当Driver得到注册了Executor之后,就可以开启正式执行我们的spark应用程序了。首先第一步,就是创建初始RDD,读取数据源,再执行之后的一系列算子。HDFS文件内容被读取到多个worker节点上,形成内存中的分布式数据集,也就是初始RDD 。
F: 这时候,Driver就会根据Job任务中的算子形成对应的task,最后提交给Executor,来分配task进行计算的线程。
G: 这时的task就会去调用对应自己任务的数据(也就是第一步初始化RDD的partition)来计算,并且task会对调用过来的RDD的partition数据执行指定的算子操作,形成新的RDD的partition,这时一个大的循环就结束了。
3. spark的shuffle介绍
待整理
4. Spark的 partitioner 都有哪些?
Partitioner主要由两个实现类:HashPartitioner和RangePartitioner。HashPartitioner主要用于tansformation算子的默认实现。RangePartitoner主要用于sortBy和sortByKey。
HashPartitoner: numPartitions方法返回传入的分区数,getPartition方法使用key的hashCode值对分区数取模得到PartitionId,写入到对应的bucket中。
RangePartioner: 相比于HashPartitoner,RangePartioner能保证每个分区中的数据量的均匀
5. coalesce和repartition区别
- coalesce用已有的partition去尽量减少数据shuffle。
- repartition创建新的partition并且使用 full shuffle。repartition使得每个partition的数据大小都粗略地相等。
- coalesce会使得每个partition不同数量的数据分布(有些时候各个partition会有不同的size)
1
2
3def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
6. coalesce如果不进行shuffle为什么会导致数据倾斜
- 进行分区缩小时,如果原分区为3个分区中的数据分别为[1,2],[3,4],[5,6],此时缩小为2若不shuffle,便可能是[1,2],[3,4,5,6]或[1,2,3,4],[5,6]
- 进行分区缩小时,如果原分区为2个分区中的数据分别为[1,2],[3,4],此时扩大为3若不shuffle,便是[1,2],[3,4],[]
7. Spark有哪几种join
spark中和join相关的算子有这几个:join, fullOuterJoin, leftOuterJoin, rightOuterJoin
join: join函数会输出两个RDD中key相同的所有项,并将它们的value联结起来,它联结的key要求在两个表中都存在,类似于SQL中的INNER JOIN。但它不满足交换律,a.join(b)与b.join(a)的结果不完全相同,值插入的顺序与调用关系有关。leftOuterJoin: leftOuterJoin会保留对象的所有key,而用None填充在参数RDD other中缺失的值,因此调用顺序会使结果完全不同。如下面展示的结果,rightOuterJoin: rightOuterJoin与leftOuterJoin基本一致,区别在于它的结果保留的是参数other这个RDD中所有的key。fullOuterJoin: fullOuterJoin会保留两个RDD中所有的key,因此所有的值列都有可能出现缺失的情况,所有的值列都会转为Some对象。
8. RDD有哪些特点
a list of partition: RDD是一个有多个partition(某个节点里的某一片连续的数据)组成的list,将数据加载为RDD是,一般会遵循数据的本地性(一般一个hdfs里的block会记载成一个partition)。a function for computing each split: RDD的每个partition上面都会有function,也就是函数应用,其作用是实现RDD之间的partition的转换。A list of dependencies on other RDDs: RDD会记录他的依赖,为了容错(重算,cache,checkpoint),也就是说在内存中的RDD操作是出错或丢失会进行重算。Optionally, a partitioner for key-value RDDs: 可选项,如果RDD里面存的数据时key-value形式,则可以传递一个自定义的partitioner进行重分区,例如这里自定义的partitioner是基于key进行分区,那则会将不容的RDD里面相同的key的数据放到同一个partition里面。Optionally, a list of prefered locations to compute each split on: 根据数据的位置进行最优位置的计算。
9. 讲一下宽依赖以及窄依赖
spark宽依赖和窄依赖
宽依赖和窄依赖的区别就是RDD之间是否存在shuffle操作。
如果父RDD分区对应1个子RDD的分区就是窄依赖,否则就是宽依赖。
1.窄依赖
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,即一个父RDD对应一个子RDD或者多个父RDD对应一个子RDD。
- map, filter, union 属于窄依赖
- co-partioned join 属于窄依赖
join分为宽依赖和窄依赖,如果RDD有相同的partitioner,那么将不会引起shuffle,因此我们可以对RDD进行Hash分区。分别对A和B用同一个函数进行Partition,比如按照首字母进行Partition,那么A和B都可以分成26个Partition,并且A1只需要和B1进行join,A1不需要和B剩下的25个Partition进行join,这样就大大的减少了join次数,最好的办法是对表进行分区,每次只取两个对应分区的数据进行join操作。
2.宽依赖
宽依赖指子RDD的每个分区都依赖于父RDD的多个分区
- group by和join 都属于宽依赖
- DAGScheduler从当前算子往前推,遇到宽依赖就生成一个stage。
3.为什么spark将依赖分位窄依赖和宽依赖
窄依赖
可以支持在一个集群的Executor上,以pipeline管道形式顺序执行多条命令。同时也由于分区内的计算收敛,不需要依赖所有分区的数据,可以并行的在不同的节点计算。所以他的失败恢复也更简单。只需要重新计算丢失的parent partition即可。宽依赖
宽依赖需要所有父分区都是可用的,必须等RDD的parent partition数据全部ready之后才能进行计算。从数据恢复的角度,shuffle dependency牵扯到RDD各级的多个parent partition。对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
10. Spark中的算子有哪些
Spark分位两大类算子:
Transformation 变换/转换算子:这种变换并不触发提交作业,完成作业中间过程处理。Transformation操作是延迟计算的,也就是说从一个RDD转换成另一个RDD的转换操作不是马上执行,需要等到有Action操作的时候才会真正触发计算。
Action行动算子:这类算子会触发SparkContext提交Job作业。
Value数据类型的Transformation算子
一对一
map算子
flatMap算子
mapPartitions算子
glom算子多对一
union算子
cartesian算子(笛卡尔)多对多
groupBy算子输出为输入子集
filter算子
distinct算子
subtract算子(差集)
sample算子(抽样调查)
takeSample算子Cache型
cache算子
persist算子
Key-Value数据类型的Transformation算子
一对一
mapValues算子 [对于(K,V)形式的类型只对V进行操作]对单个RDD或两个RDD聚集
combineByKey算子
reduceByKey算子
partitionBy算子
Cogroup算子连接
join算子
leftOutJoin 和 rightOutJoin算子
Action算子
无输出
foreach算子HDFS算子
saveAsTextFile算子
saveAsObjectFile算子Scala集合和数据类型
collect算子
collectAsMap算子
reduceByKeyLocally算子
lookup算子
count算子
top算子
reduce算子
fold算子
aggregate算子
countByValue
countByKey
11. RDD的缓存级别
- NONE:什么类型都不是
- DISK_ONLY:磁盘
- DISK_ONLY_2:磁盘;双副本
- MEMORY_ONLY:内存;反序列化;把RDD作为反序列化的方式存储,假如RDD的内容存不下,剩余的分区在以后需要时会重新计算,不会刷到磁盘上
- MEMORY_ONLY_2:内存;反序列化;双副本。
- MEMORY_ONLY_SER:内存;序列化;这种序列化方式,每一个partition以字节数据存储,好处是能带来更好的空间存储,但CPU耗费高
- MEMORY_ONLY_SER_2:内存;序列化;双副本
- MEMORY_AND_DISK:内存 + 磁盘;反序列化;双副本;RDD以反序列化的方式存内存,假如RDD的内容存不下,剩余的会存到磁盘
- MEMORY_AND_DISK_2:内存 + 磁盘;反序列化;双副本
- MEMORY_AND_DISK_SER:内存 + 磁盘;序列化
- MEMORY_AND_DISK_SER_2:内存 + 磁盘;序列化;双副本
12. RDD懒加载是什么意思
Transformation 操作是延迟计算的,也就是说从一个RDD转换生成另一个RDD的转换操作不是马上执行,需要等到有Acion操作的时候才会真正触发运算,这也就是懒加载。
13. 讲一下spark的几种部署方式
目前,除了local模式为本地调试模式以为, Spark支持三种分布式部署方式,分别是standalone、spark on mesos和 spark on YARN。
Standalone模式
即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。从一定程度上说,该模式是其他两种的基础。目前Spark在standalone模式下是没有任何单点故障问题的,这是借助zookeeper实现的,思想类似于Hbase master单点故障解决方案。Spark On YARN模式
spark on yarn 的支持两种模式:
yarn-cluster:适用于生产环境;
yarn-client:适用于交互、调试,希望立即看到app的输出
yarn-cluster和yarn-client的区别在于yarn appMaster,每个yarn app实例有一个appMaster进程,是为app启动的第一个container;负责从ResourceManager请求资源,获取到资源后,告诉NodeManager为其启动container。yarn-cluster和yarn-client模式内部实现还是有很大的区别。如果你需要用于生产环境,那么请选择yarn-cluster;而如果你仅仅是Debug程序,可以选择yarn-client。Spark On Mesos模式
略
14. Spark on yarn模式下的cluster模式和client模式有什么区别
- yarn-cluster适用于生产环境。而yarn-client适用于交互和调试,也就是希望快速地看到application的输出。
- yarn-cluster 和 yarn-client 模式的区别其实就是 Application Master 进程的区别,yarn-cluster 模式下,driver 运行在 AM(Application Master)中,它负责向 YARN 申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉 Client,作业会继续在 YARN 上运行。然而 yarn-cluster 模式不适合运行交互类型的作业。而 yarn-client 模式下,Application Master 仅仅向 YARN 请求 executor,Client 会和请求的container 通信来调度他们工作,也就是说 Client 不能离开。
15. spark运行原理,从提交一个jar到最后返回结果
- spark-submit提交代码,执行new SparkContext(), 在SparkContext里构造DAGScheduler和TaskScheduler。
- TaskScheduler会通过后台的一个进程,连接master,向master注册Application。
- Master接收到Application请求后,会使用相应的资源调用算法。在Worker上为这个Application启动多个Executor。
- Executor启动后,会自己反向注册到TaskScheduler中。所有Executor都注册到Driver上之后,SparkContext结束初始化,接下来往下执行我们自己的代码。
- 每执行到一个 Action,就会创建一个 Job。Job 会提交给 DAGScheduler。
- DAGScheduler 会将 Job划分为多个 stage,然后每个 stage 创建一个 TaskSet。
- TaskScheduler 会把每一个 TaskSet 里的 Task,提交到 Executor 上执行。
- Executor 上有线程池,每接收到一个 Task,就用 TaskRunner 封装,然后从线程池里取出一个线程执行这个 task。(TaskRunner 将我们编写的代码,拷贝,反序列化,执行 Task,每个 Task 执行 RDD 里的一个 partition)
16. Spark的stage是如何划分的
stage的划分依据就是看是否产生了shuffle(即宽依赖),遇到一个shuffle操作就划分为前后两个stage。
17. Spark2.0为什么放弃了akka而用netty
- 很多Spark用户也使用Akka,但是由于Akka不同版本之间无法互相通信,这就要求用户必须使用跟Spark完全一样的Akka版本,导致用户无法升级Akka。
- Spark的Akka配置是针对Spark自身来调优的,可能跟用户自己代码中的Akka配置冲突。
- Spark用的Akka特性很少,这部分特性很容易自己实现。同时,这部分代码量相比Akka来说少很多,debug比较容易。如果遇到什么bug,也可以自己马上fix,不需要等Akka上游发布新版本。而且,Spark升级Akka本身又因为第一点会强制要求用户升级他们使用的Akka,对于某些用户来说是不现实的。
18. Spark的各种HA,master/worker/executor的ha
Master异常
spark可以在集群运行时启动一个或多个standby Master,当 Master 出现异常时,会根据规则启动某个standby master接管,在standlone模式下有如下几种配置ZOOKEEPER
集群数据持久化到zk中,当master出现异常时,zk通过选举机制选出新的master,新的master接管是需要从zk获取持久化信息FILESYSTEM
集群元数据信息持久化到本地文件系统, 当master出现异常时,只需要在该机器上重新启动master,启动后新的master获取持久化信息并根据这些信息恢复集群状态CUSTOM
自定义恢复方式,对 standloneRecoveryModeFactory 抽象类 进行实现并把该类配置到系统中,当master出现异常时,会根据用户自定义行为恢复集群None
不持久化集群的元数据, 当 master出现异常时, 新启动的Master 不进行恢复集群状态,而是直接接管集群
Worker异常
Worker以定时发送心跳给Master,让Master知道Worker的实时状态,当Worker出现超时,Master 调用 timeOutDeadWorker 方法进行处理,在处理时根据 Worker 运行的是 Executor 和 Driver 分别进行处理。
如果是Executor, Master先把该 Worker 上运行的Executor 发送信息ExecutorUpdate给对应的Driver,告知Executor已经丢失,同时把这些Executor从其应用程序列表删除, 另外, 相关Executor的异常也需要处理
如果是Driver, 则判断是否设置重新启动,如果需要,则调用Master.shedule方法进行调度,分配合适节点重启Driver, 如果不需要重启, 则删除该应用程序Executor异常
Executor发生异常时由ExecutorRunner捕获该异常并发送ExecutorStateChanged信息给Worker
Worker接收到消息时, 在Worker的 handleExecutorStateChanged 方法中, 根据Executor状态进行信息更新,同时把Executor状态发送给Master
Master在接受Executor状态变化消息之后,如果发现其是异常退出,会尝试可用的Worker节点去启动Executor
19. spark的内存管理机制,spark 1.6前后分析对比, spark2.0 做出来哪些优化
20. 讲一下spark中的广播变量
broadcast 就是将数据从一个节点发送到其他各个节点上去。这样的场景很多,比如 driver 上有一张表,其他节点上运行的 task 需要 lookup 这张表,那么 driver 可以先把这张表 copy 到这些节点,这样 task 就可以在本地查表了。
为什么broadcast是只读变量
这就涉及到一致性的问题,如果变量可以被更新,name一旦变量被某个节点更新,其他的节点要不要一块更新?如果多个节点同事更新,更新顺序是什么?怎么做同步?为了避免维护数据一致性问题,Spark 目前只支持 broadcast 只读变量。为什么broadcast到节点而不是到每个task
因为每个task是一个线程,而且同在一个进程运行tasks都属于同一个application。因此每个节点(executor)上放一份就可以被所有task共享。怎么实现broadcast
Driver先建一个本地文件夹用于存放需要broadcast的data,并启动一个可以访问该文件的HttpServer。当调用val bdata = sc.broadcast(data)时就把data写入文件夹,同时写入driver自己的blockManger中(StorageLevel 为内存+磁盘)。如果func用到了 bdata,那么driver submitTask() 的时候会将bdata一同func进行序列化得到 serialized task,注意序列化的时候不会序列化bdata中包含的data。上一章讲到 serialized task从driverActor传递到executor时使用Akka的传消息机制,消息不能太大,而实际的data可能很大,所以这时候还不能broadcast data。driver 为什么会同时将 data 放到磁盘和 blockManager 里面?放到磁盘是为了让 》HttpServer 访问到,放到 blockManager 是为了让 driver program 自身使用 bdata 时方便(其实我觉得不放到 blockManger 里面也行)。
那么什么时候传送真正的 data?在 executor 反序列化 task 的时候,会同时反序列化 task 中的 bdata 对象,这时候会调用 bdata 的 readObject() 方法。该方法先去本地 blockManager 那里询问 bdata 的 data 在不在 blockManager 里面,如果不在就使用下面的两种 fetch 方式之一去将 data fetch 过来。得到 data 后,将其存放到 blockManager 里面,这样后面运行的 task 如果需要 bdata 就不需要再去 fetch data 了。如果在,就直接拿来用了。
下面探讨 broadcast data 时候的两种实现方式:
- HttpBroadcast
无 - TorrentBroadcast
无
21. 什么是数据倾斜,怎样去处理数据倾斜
参考文章:Spark学习——数据倾斜
[spark 面试]数据倾斜
数据倾斜是一种很常见的问题,比方WordCount中某个Key对应的数据量非常大,就会产生数据倾斜,导致两个后果:
- OOM(单或少数的节点)
- 拖慢整个Job执行时间(其他已经完成的节点都在等未完成的节点)
数据倾斜主要分为两类:聚合倾斜和join倾斜
聚合倾斜
- 双重聚合(局部聚合+全局聚合)
- 场景:对RDD进行reduceByKey等聚合类shuffle算子,SparkSQL的groupBy做分组聚合这两种情况。
- 思路:首先通过map给每个key打上n以内的随机数的前缀并进行局部聚合,即(hello, 1) (hello, 1) (hello, 1) (hello, 1)变为(1_hello, 1) (1_hello, 1) (2_hello, 1),并进行reduceByKey的局部聚合,然后再次map将key的前缀随机数去掉再次进行全局聚合。
- 原理: 对原本相同的key进行随机数附加,变成不同key,让原本一个task处理的数据分摊到多个task做局部聚合,规避单task数据过量。之后再去随机前缀进行全局聚合;
- 优点:效果非常好(对聚合类Shuffle操作的倾斜问题);
- 缺点:范围窄(仅适用于聚合类的Shuffle操作,join类的Shuffle还需其它方案)
- 双重聚合(局部聚合+全局聚合)
join倾斜
将reduce join转化为map join
- 场景: 对RDD或Spark SQL使用join类操作或语句,且join操作的RDD或表比较小(百兆或1,2G);
- 思路: 使用broadcast和map类算子实现join的功能替代原本的join,彻底规避shuffle。对较小RDD直接collect到内存,并创建broadcast变量;并对另外一个RDD执行map类算子,在该算子的函数中,从broadcast变量(collect出的较小RDD)与当前RDD中的每条数据依次比对key,相同的key执行你需要方式的join;
- 原理: 若RDD较小,可采用广播小的RDD,并对大的RDD进行map,来实现与join同样的效果。简而言之,用broadcast-map代替join,规避join带来的shuffle(无Shuffle无倾斜);
- 优点:效果很好(对join操作导致的倾斜),根治;
- 缺点:适用场景小(大表+小表),广播(driver和executor节点都会驻留小表数据)小表也耗内存
采样倾斜key并分拆join操作
- 场景:两个较大的(无法采用方案五)RDD/Hive表进行join时,且一个RDD/Hive表中少数key数据量过大,另一个RDD/Hive表的key分布较均匀(RDD中两者之一有一个更倾斜);
- 思路:
- 对更倾斜rdd1进行采样(RDD.sample)并统计出数据量最大的几个key;
- 对这几个倾斜的key从原本rdd1中拆出形成一个单独的rdd1_1,并打上0~n的随机数前缀,被拆分的原rdd1的另一部分(不包含倾斜key)又形成一个新rdd1_2;
- 对rdd2过滤出rdd1倾斜的key,得到rdd2_1,并将其中每条数据扩n倍,对每条数据按顺序附加0~n的前缀,被拆分出key的rdd2也独立形成另一个rdd2_2; 【个人认为,这里扩了n倍,最后union完还需要将每个倾斜key对应的value减去(n-1)】
- 将加了随机前缀的rdd1_1和rdd2_1进行join(此时原本倾斜的key被打散n份并被分散到更多的task中进行join); 【个人认为,这里应该做两次join,两次join中间有一个map去前缀】
- 另外两个普通的RDD(rdd1_2、rdd2_2)照常join;
- 最后将两次join的结果用union结合得到最终的join结果。 原理:对join导致的倾斜是因为某几个key,可将原本RDD中的倾斜key拆分出原RDD得到新RDD,并以加随机前缀的方式打散n份做join,将倾斜key对应的大量数据分摊到更多task上来规避倾斜;
- 优点: 前提是join导致的倾斜(某几个key倾斜),避免占用过多内存(只需对少数倾斜key扩容n倍);
- 缺点: 对过多倾斜key不适用。
用随机前缀和扩容RDD进行join
- 场景:RDD中有大量key导致倾斜;
- 思路:与方案六类似
- 查看RDD/Hive表中数据分布并找到造成倾斜的RDD/表;
- 对倾斜RDD中的每条数据打上n以内的随机数前缀;
- 对另外一个正常RDD的每条数据扩容n倍,扩容出的每条数据依次打上0到n的前缀;
- 对处理后的两个RDD进行join。
- 原理: 与方案六只有唯一不同在于这里对不倾斜RDD中所有数据进行扩大n倍,而不是找出倾斜key进行扩容;
- 优点: 对join类的数据倾斜都可处理,效果非常显著;
- 缺点: 缓解,扩容需要大内存
22. 分析一下一段spark代码中哪些部分在Driver端执行,哪些部分在Worker端执行
Driver Program是用户编写的提交给Spark集群执行的application,它包含两部分
- 作为驱动: Driver与Master、Worker协作完成application进程的启动、DAG划分、计算任务封装、计算任务分发到各个计算节点(Worker)、计算资源的分配等。
- 计算逻辑本身,当计算任务在Worker执行时,执行计算逻辑完成application的计算任务
一般来说transformation算子均是在worker上执行的,其他类型的代码在driver端执行